一.Scalability 是什么?
Scalability is the property of a system to handle a growing amount of work by adding resources to the system.
(摘自Scalability)
即,通过向系统添加资源的方式应对不断增加的工作量
那么,如何添加资源呢?
二.扩展硬件资源
加资源有两种加法,纵向扩展与横向扩展
纵向扩展
纵向扩展(Vertical scaling),即提升单机配置,对单台机器加内存、处理器、硬盘等硬件资源。投入足够多的预算,就能砸出一台配置豪华的服务器
然而,这种单点强化式的扩展不可能无限进行下去,因为很快会达到顶配(或者耗光预算),所以不算是个完整的解决方案
横向扩展
另一种加资源的方式是横向扩展(Horizontal scaling),即加机器,数量上从一台扩展到多台,多服务器形成拓扑结构。投入足够多的预算,就能拥有一个机房,甚至遍布全球的数据中心
理论上,横向扩展是没有上限的,我们可以使用无限多台服务器支撑无限多的用户请求。而且,横向扩展相当于引入了冗余(Replication),比单机更可靠
但机器由一台变成多台之后,面临的最大问题是资源分配,如何充分利用这些机器?即,如何均衡负载?
三.负载均衡
负载均衡器(Load Balancer)负责把用户请求分发到多个服务器上,具体的,公网 Load Balancer 根据路由规则分发入站 HTTP 请求,决定把数据包实际发送给哪个内网服务器
常见的分发策略有:
基于负载情况分发
轮流均分
基于资源依赖情况分发
当然,最理想的分配策略是基于服务器当前负载情况分发,比如把新请求交给不太忙的服务器,但问题在于负载情况不那么容易精确获知
而最简单的分配策略是轮流(Round robin),比如第一次请求 URL 时返回 Server1 的 IP 地址,第二次返回 Server2 的 IP 地址……然而,轮流工作意味着一视同仁,假定每个请求的工作量相同,每个 Server 的处理能力也相同,但实际场景大多不满足这样的条件
P.S.不建议用 DNS 来充当负载均衡器(添加一系列 A 记录),因为操作系统以及应用层的 DNS 缓存会破坏这种轮流均分的机制
另一方面,不同类型的服务对资源的依赖情况(带宽、存储、计算能力等)可能不一样,所以也可以采用专用服务器,并根据资源依赖情况分发,比如对 gif、jpg、image、video 等使用不同的专用服务器,并通过子域名等方式来区分
会话保持
加一层 Load Balancer 解决了资源分配的问题,但又带来了一个新问题:前后两个请求可能被负载均衡器转发到不同的服务器上,如果这两个请求有关联(比如登录和下单),前置的状态就会丢失(用户刚登录完点击下单接着可能又要求登录)
一种解决办法是粘滞会话(Sticky sessions),把相关联的请求转发给同一台服务器:
Send all requests in a user session consistently to the same backend server.
(摘自Load balancing (computing))
比如在 Cookie 中带上服务器的标识信息,之后的一系列请求都转给那台服务器
P.S.但 Cookie 可能会被禁用,因此一般会综合使用多种方式来保持会话
另一种方案是把 Session“外包”出去,存放到公共的地方,供其它服务器共享访问:
Every server contains exactly the same codebase and does not store any user-related data, like sessions or profile pictures, on local disc or memory. Sessions need to be stored in a centralized data store which is accessible to all your application servers.
至此,我们增加了一些机器,并通过一个负载均衡器让多台机器共同分担运转起来了,看起来一切都很完美……那么,如果这个负载均衡器 down 掉了呢?
四.引入冗余
引入负载均衡器之后,所有请求都要先经过负载均衡器,负载均衡器就成为了网络拓扑结构中脆弱的单点,一旦发生故障,身后的所有服务器就都无法访问了
冗余负载均衡器
为了避免单点故障(Single Point of Failure),负载均衡器同样需要引入冗余(比如使用一对儿负载均衡器),一般有两种故障转移(Fail-over)模式:
主动-被动(Active-passive):主动的工作,被动的备用,主动的 down 掉后被动的上
主动-主动(Active-active):同时工作,一个 down 掉之后不影响
无论采用哪种工作模式,引入冗余都能缩短宕机时间,提升系统可靠性与可用性
五.扩展数据库
理论上,有了可靠的负载均衡机制,我们就能将 1 台服务器轻松扩展到 n 台,然而,如果这 n 台机器仍然使用同一数据库的话,很快数据库就会成为系统的性能瓶颈和可靠性瓶颈
如法炮制,我们可以扩展数据库的处理能力,多加几个库,即引入冗余,一般有两种模式:
主从复制:主库直接读写,从库在主库收到查询时,执行相同的查询。如果主库 down 掉了,就在从库里面提升一个作为主库
主主复制:都可以写,写操作也会被复制到另一个库中
数据库引入冗余之后,甚至还能对多个从库进行负载均衡(尤其适用于读密集的场景):

以及按内容特点分区存储(Partitioning):
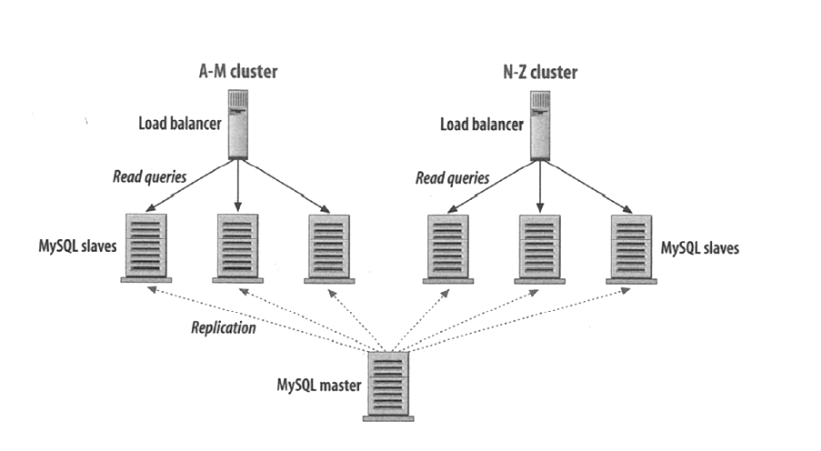
将姓名以 A-M 开头的数据存放到左边的几个数据库,N-Z 开头的存放到右边
同时,也可以通过分库分表(Sharding)、反范式化(Denormalization)、SQL 调优(SQL tuning)等方式优化查询
到这里,数据库层所能做的扩展优化似乎已经达到极限了,那么,还有其它办法能够减轻数据库的压力吗?
六.缓存
另一种思路是尽可能减少数据库操作,比如在 Web 服务与数据之间增加一层内存缓存,查询时优先走缓存,缓存中没有才从数据库中取
一般有两种缓存模式:
缓存查询结果
缓存对象
缓存所有查询结果最大的问题在于,数据发生变化后,很难判定缓存是否过期:
It is hard to delete a cached result when you cache a complex query (who has not?). When one piece of data changes (for example a table cell) you need to delete all cached queries who may include that table cell.
而缓存对象是指缓存根据原始数据组装出的数据模型(比如一个 Java 类实例),优势在于获知数据变化之后,能够丢弃与之具有逻辑关联的数据对象,从而解决缓存过期的难题
至此,我们已经自下而上地讨论了包括硬件资源、数据库、缓存在内的可扩展性问题,那么,Web 服务自身应该如何扩展?
七.异步处理
对于 Web 服务而言,提升可扩展性的主要途径是将耗时的同步工作改成异步处理,从而允许将这些工作“外包”给多个 Worker 去做,或者提前完成能够预知的部分