写在前面
UC Berkeley 在 2019 年 2 月 10 日发布了一篇关于 Serverless 的论文,引发了业界这几个月以来对 Serverless 的热议
伯克利研究员们认为 Serverless 几乎可以处理所有系统管理操作,让开发者更轻松地使用云。能够大大简化云编程,同时也标志着一种类似于从汇编语言到高级编程语言的演变:
Serverless cloud computing handles virtually all the system administration operations needed to make it easier for programmers to use the cloud. It provides an interface that greatly simplifies cloud programming, and represents an evolution that parallels the transition from assembly language to high-level programming languages.
甚至认为Serverless 将主导云计算的未来:
Just as the 2009 paper identified challenges for the cloud and predicted they would be addressed and that cloud use would accelerate, we predict these issues are solvable and that serverless computing will grow to dominate the future of cloud computing.
一.10 年前的 6 个预言
10 年前(2009 年 2 月 10 日),UC Berkeley 在一篇关于 Cloud Computing 的论文中指出了云计算的 6 大潜在优势:
能按需提供无限的计算资源
云用户无需预估资源
提供即用即付的短期计算资源
超大型数据中心形成的规模经济将极大地降低成本
通过资源虚拟化简化操作并提高利用率
通过多路复用来提高硬件利用率
P.S.关于这些预言的详细信息,见伯克利研究员们眼中的 Cloud Computing
时至如今,这些优势基本都实现了。但操作上的复杂性却仍然困扰着云用户,多路复用的优势也没能完全发挥出来:
云计算减轻了管理物理基础设施的负担,却产生了大量同样需要管理的虚拟资源
多路复用能在批处理的场景(比如 MapReduce 或高性能计算)大显身手,而对于有状态的服务(比如数据管理系统等企业应用)却很难发挥作用
P.S.多路复用是一种广泛应用于通信领域的资源共享技术,包括分时复用(Time-division multiplexing)、分频复用(Frequency-division multiplexing)等
原因在于市场选择了更低程度的资源抽象方式,云用户像使用物理硬件一样控制整个资源栈,仍需要考虑:
可用性冗余(避免单点故障)
异地容灾
负载均衡
弹性伸缩
监控
日志(用于调试或性能诊断)
系统升级(安全补丁等)
可移植性(迁移到新实例)
二.Serverless Computing 登场
概念定义
意识到易用性方面的需求后,Amazon 在 2015 年推出了 AWS Lambda 服务,即云函数(cloud functions),继而引起了对无服务器计算(serverless computing)理念的广泛关注:
Serverless suggests that the cloud user simply writes the code and leaves all the server provisioning and administration tasks to the cloud provider.
将服务器相关的配置管理工作统统交给云供应商去做,以减轻用户管理云资源的负担
因此,Serverless Computing 并不是说不需要 server 就能 computing,而是对用户而言不必花很大精力去管理 server。同样的,Serverless 服务能够(自动)弹性伸缩,无需显式预配资源,并且按使用情况计费
另一方面,Serverless 还带来了一种模式转变——允许交由供应商全权操作,这让细粒度的多租户多路复用成为了可能:
Serverless computing, on the other hand, introduces a paradigm shift that allows fully offloading operational responsibilities to the provider, and makes possible fine-grained multi-tenant multiplex- ing.
Serverless 的核心是 FaaS(Function as a Service),但云平台通常还提供 Serverless 框架来满足 BaaS (Backend as a Service)等特定应用程序要求。因此,可以简单理解为:
Serverless computing = FaaS + BaaS
基本架构
Serverless 层处于应用层和基础云平台层之间,用来简化云编程:
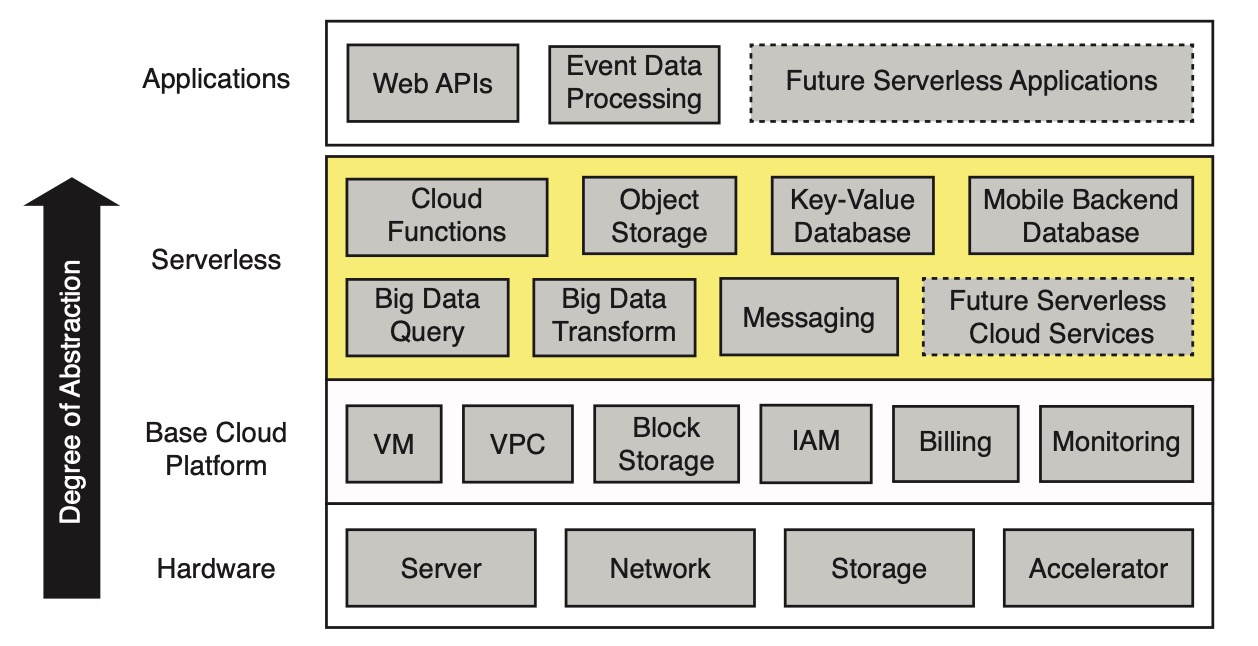
Architecture of the serverless cloud
其中,云函数(Cloud functions,比如 FaaS)提供常规计算,辅以特定的 BaaS 产品生态(比如对象存储、数据库、消息机制等)。基础平台包括虚拟机(VM)、专用网络(VPC)、虚拟化数据块存储、身份和访问管理(IAM)以及计费和监控
Serverless 与 Serverful
用户只需要在 Serverless 平台用高级语言写一些云函数,再选择触发该函数执行的事件即可。之后的事情由 Serverless 系统来搞定,实例选择、伸缩、部署、容错、监控、日志、安全补丁等等全都不用关心,通过提升云资源的易用性来简化应用开发
云背景下,对云开发者而言,传统方式(Serverful Computing)就像是在使用底层汇编语言,哪怕是c = a + b的简单计算也要经过一系列操作:
选择 1 个或 2 个寄存器(预配或找出可用的资源)
把值加载到寄存器中(将代码和数据加载进去)
执行算术运算(执行计算)
存储计算结果(返回或存储结果,最后释放资源)
而 Serverless 方式则像是用 Python 之类的高级语言在编程,免去了这些繁琐的操作
因此,Serverless 最具潜力的地方就在于能给云开发者带来这种类似于向高级语言迈进的好处:
The aim and opportunity in serverless computing is to give cloud programmers benefits similar to those in the transition to high-level programming languages.
高级编程环境的一些特性在 Serverless 中有天然的相似之处,例如,自动化的内存管理能把开发者从内存资源的管理工作中解放出来,而Serverless 要将开发者从服务器资源的管理工作中解放出来
确切地说,Serverless 与 Serverful 最关键的区别在于:
分离了计算和存储:存储和计算分开伸缩、独立预配、独立定价。通常存储由单独的云服务提供,并且计算是无状态的
不用管理资源分配就能执行代码:用户提供一段代码,云自动预配资源来执行
按使用付费,而不是按所分配的资源付费:按代码执行的相关维度付费(比如执行时间),而不是按云平台的相关维度(比如所分配 VM 的大小和数量)
三.关键特点
听起来与先前的一些模式似乎没太大区别:
现有的一些 PaaS 产品,比如 Firebase、Heroku、Parse 等好像就是 Serverless
80 年代的 Web 托管环境不也能提供 Serverless 声称的好处吗?
听起来像是 10 年前的 Google AppEngine,但这在 Serverless 理念出现之前就已经被市场拒绝了呀
那么,与之前的这些模式相比,Serverless 的关键特点是什么?
伸缩性
伸缩性方面,AWS Lambda 能够精确跟踪负载情况,按需快速响应扩展,闲时能够缩减到零资源、零成本。并且能以更细的粒度计费(100ms),而传统的弹性伸缩服务通常按小时计费
最关键的是,Serverless 的出发点在于按代码实际执行的时间计费,而不是为程序执行所保留的资源:
In a critical departure, it charged the customer for the time their code was actually executing, not for the resources reserved to execute their program.
这种区别保证了云供应商能在弹性伸缩这一点上与云用户共担风险、共享利益(skin in the game),继而促进高效的资源分配
强隔离性
Serverless 依靠强大的性能和安全隔离性实现多租户共享硬件
对于云函数,VM 隔离是目前的标准方案,但预配 VM 可能需要几秒钟,所以云供应商会使用一些精细的技术来加快函数执行环境的创建。比如 AWS Lambda 维护了一个热 VM 池(a “warm pool” of VM)管理能够立即分配给租户的 VM,以及一个活跃实例池(an “active pool” of instances)管理那些已经在执行或准备好执行函数的实例
资源生命周期的管理与多租户装箱策略(multi-tenant bin packing)是实现高利用率的关键,对 Serverless 而言至关重要。大多利用容器、单核、库操作系统(library OS)或语言 VM 等技术来减少多租户隔离的开销,例如 Google App Engine 使用的 gVisor、AWS Lambda 中的 Firecracker VM,以及 CloudFlare Workers 平台采用 Web 浏览器沙盒技术来实现 JavaScript 云函数间的多租户隔离
平台灵活性
PaaS 服务通常与特定用例密切相关,而 Serverless 允许用户使用自己的类库,所能支持的应用程序比 PaaS 更广泛
而且,Serverless 运行在现代化大型数据中心,所能支持的运行规模比旧的共享 web 托管环境大得多
服务生态支持
云函数(比如 FaaS)成功推广了 Serverless 模式,其中一部分归功于一些自公有云以来就存在的 BaaS 服务(比如 AWS S3),这些 BaaS 服务都可以看作面向特定领域、高度优化的 Serverless 实现,而云函数是一种更通用的 Serverless 表现形式:
| Service | Programming Interface | Cost Model |
|---|---|---|
| Cloud Functions | Arbitrary code | Function execution time |
| BigQuery/Athena | SQL-like query | The amount of data scanned by the query |
| DynamoDB | puts() and gets() | Per put() or get() request + storage |
| SQS | enqueue/dequeue events | per-API call |
四.核心优势
对云供应商而言,Serverless 能够促进业务增长,简化云编程,吸引新用户并帮助现有用户充分利用云资源。此外,运行时间短、内存占用低以及无状态的特性有利于统计复用。在运行这些任务时,云供应商更容易发现那些没有被用到的资源。甚至还能更好地利用那些不太受欢迎的机器(比如旧机器),因为实例类型是由云供应商来定的,这两点都能在现有资源的基础上立即增加收益
对云用户而言,除了提高编程生产力之外,大多数场景下还能节省成本,因为对底层服务器的利用率提高了。在没有任何云基础设施的情况下也能直接部署函数,不仅省去了部署时间,让云用户专注于应用程序自身的问题,还能节省资金,因为函数只在事件发生的时候才执行,细粒度的计费方式(目前是 100ms)意味着按实际使用付费,而不是按所保留的资源付费
从研究角度来看,Serverless 是一种新的通用计算抽象,有望成为云计算的未来。因为Serverless 将云部署级别从 x86 机器代码提升到了高级编程语言,从而实现架构创新。如果 ARM 或 RISC-V 比 x86 性价比更高,Serverless 也能轻松变更指令集。并且云供应商还能通过研究面向(编程)语言的优化以及特定领域的特殊架构来加快用 Python 等语言编写的程序
P.S.99%的云计算机用的都是 x86 架构(x86 微处理器 + x86 指令集)
五.现有 Serverless 平台的局限性
现如今,云函数已经成功应用于多种工作,包括 API 服务、事件流处理和有限的 ETL(Extract-Transform-Load,数据处理),那么为什么不能承载更多的通用服务呢?
原因在于:
对细粒度操作的存储支持不足:目前的云存储服务无法满足云函数的需要
缺少细粒度协调:没有多任务协调机制
标准通信模式下性能很差:多任务间无法共享、聚合数据
性能不可预测:虽然比传统的基于 VM 的实例启动延迟更低,但对于某些应用而言启动新实例的延迟还是太高了
细粒度操作的存储不足
Serverless 平台的无状态性让支持需要共享细粒度状态的应用变得很难实现,目前主要受限于云存储服务
对象存储服务(如 AWS S3、Azure Blob Storage、Google Cloud Storage)虽然能够快速扩展,并且提供了廉价的长期对象存储,但存在很高的访问成本和延迟。近期测试表明读/写小对象至少需要 10ms,维持 10 万 IOPS(每秒读写次数,Input/Output Operations Per Second)的成本是 30 美元/分钟,要比 AWS ElastiCache 实例高 3 到 4 个数量级,并且 ElastiCache 实例只有亚毫秒级读写延迟,其 IOPS 甚至能超过 100K
KV 数据库(如 AWS DynamoDB、Google Cloud Datastore、Azure Cosmos DB)都提供了高 IOPS 支持,但都很贵,而且无法快速扩展。虽然云供应商也提供了基于流行开源项目(如 Memcached 或 Redis)的内存存储实例,但缺少容错性支持,也无法像 Serverless 平台那样自动伸缩
在 Serverless 基础设施上搭建的应用需要预配透明的存储服务,即能随计算自动伸缩的存储服务。不同应用程序可能对持久性、可用性、延迟、性能等有不同要求,因此可能需要临时与持久化两种 Serverless 存储选项
缺少细粒度协调
为了支持有状态的应用,Serverless 框架需要提供一种协调多任务的方式,例如,A 任务用到了 B 任务的输出,A 就必须有办法知道什么时候输入准备好了,即使 A 和 B 位于不同节点上。许多致力于保证数据一致性的协议也需要类似的协调机制
现有的云存储服务都没有通知能力,云供应商虽然提供了独立的通知服务(如 SNS、SQS),但存在很高的延迟(有时几百 ms),而且细粒度协调的使用成本也很高。虽然有一些相关改善研究(比如 Pocket),但还没有被云供应商所采用
因此,应用程序要么管理一个具有通知能力的基于 VM 的系统(例如 ElastiCache、SAND),要么实现自己的通知机制,比如让云函数之间通过一个长期运行着的基于 VM 的汇聚服务器(rendezvous server)来通信。这种限制引发了对一些新 Serverless 变体的探索,比如命名函数实例允许通过直接寻址来访问其内部状态(例如 Actors as a Service)
标准通信模式下性能很差
广播(broadcast)、聚合(aggregation)、shuffle 机制等分布式系统中的常见通信模式在云函数环境复杂度骤增:

communication patterns for distributed applications
原因在于 VM 实例在发送数据之前和收到数据之后有机会在任务之间共享、聚合或合并数据,而在 Serverless 下没有
具体的,基于 VM 的方案中,所有运行在同一实例上的任务能够共享广播传来的数据,或者在给其它实例发送部分结果之前进行本地聚合。因此,广播和聚合的通信复杂度是 O(N),其中 N 是系统中 VM 实例的数量。而在云函数环境下,通信复杂度为 O(N × K),其中 K 是每个 VM 上的函数数量
在 shuffle 机制下这种差异更大,基于 VM 的方案中所有本地任务能把数据合并到一起,所以两个 VM 之间只需要传递一条消息。假设发送方和接收方数量相等的话,需要发送 N^2 条消息,而在云函数方案下需要发送(N × K)^2 条消息。由于云函数拥有的 CPU 核心数量比 VM 少得多,K 一般是 10 到 100,再加上应用程序无法控制云函数的位置,实际可能要比等效的 VM 方案多发送 2 到 4 个数量级的数据
P.S.这些通信模式多用于机器学习与大数据分析应用中
性能不可预测
影响冷启动延迟的因素有 3 点:
启动云函数所需的时间
初始化该函数所需软件环境的时间,比如加载 Python 库
用户代码中特定应用程序初始化的时间
比起后两者的开销,前者就不算什么了,比如启动云函数只需要 1 秒,而加载所有应用程序类库可能需要几十秒
另一个阻碍因素是硬件资源的可变性,因为云供应商能够灵活选择底层服务器(甚至可能会遇到不同时代的 CPU)。对于这个问题,云供应商需要在最大限度地利用资源与性能可预测性之间进行权衡
六.理想的 Serverless Computing
要让更多应用程序受益于 Serverless,主要面临着抽象、系统、网络、安全、架构等方面的挑战
抽象
资源需求
开发者只能限制云函数的内存大小和执行时间,而无法控制其它资源需求,比如 CPU、GPU 或其它类型的加速器
一种方式是让开发者显式指定这些资源需求,但会让云供应商更难通过统计复用实现高利用率,因为对云函数调度施加了更多约束。而且有违 Serverless 精神,因为增加了云应用开发者的资源管理负担
另一种更好的选择是提升抽象层级,由云供应商来推断资源需求而不由开发者指定。比如云供应商可以通过静态代码分析、分析上一次运行情况或者动态编译源码来实现。自动预配适当的内存听起来很诱人,但充满挑战,尤其是在高级语言具有自动垃圾回收机制时,甚至有些研究建议这些语言运行时应该与 Serverless 平台集成起来
数据依赖
目前的云函数平台不知道两个云函数之间的数据依赖关系,导致这些函数之间可能需要交换大量数据。还可能导致不理想的节点分布,引发更低效的通信模式
一种解决办法是云供应商暴露一个能够让应用程序指定其计算图的的 API,以支持更好的节点分布决策,将通信降到最低,进而提升性能。实际上,很多通用分布式框架(如 MapReduce、Apache Spark、Apache Beam/Cloud Dataflow)、并行 SQL 引擎(如 BigQuery, Azure Cosmos DB)以及编排框架(如 Apache Airflow)已经在内部生成了这样的计算图。原则上,这些系统通过改造也能运行在云函数环境,并把计算图暴露给云供应商
P.S.AWS Step Functions 已经在这么做了,提供了一种状态机语言和 API
系统
高性能、预配透明且经济实惠的存储
对于临时与持久化两种存储需求,临时存储主要用来解决云函数之间传递状态时的速度和延迟问题
提供临时存储的一种方案是构建具有优化网络栈的分部式内存服务,以保证微秒级延迟。并像操作系统为进程提供透明的内存预配一样,自动伸缩,并随应用生命周期创建/释放,还要提供安全隔离。但目前 RAMCloud、FaRM 能保证低延迟和高 IOPS,却没有提供多租户隔离,而 Pocket 无法自动伸缩,需要预先分配存储
而且,通过统计复用,临时存储要比目前的 Serverful 模式内存效率更高,能将 VM 实例中应用程序用不完的那部分内存也利用起来
虽然 OLTP(On-Line Transaction Processing)之类的数据库功能可能会越来越多地以 BaaS 形式提供,但对于需要比 Serverless 应用更长的持久化存储的应用,还应该实现高性能的 Serverless 持久存储
对于持久化存储,可以利用基于 SSD 的分布式存储辅以分布式内存缓存,比如 Anna KV 数据库,通过结合多个现有的云存储服务来实现高性价比和高性能,但这种设计的关键点是如何在大量尾部访问分布的情况下实现低尾延迟(tail latency),此时内存缓存能力可能比 SSD 能力低得多。此外,利用有望实现微秒级访问时间的新存储技术也是一种可能的解决方案
与 Serverless 临时存储类似,持久化存储服务也应该是预配透明、安全隔离的。不同的是,Serverless 持久化存储只能显式释放资源,像传统存储系统一样。当然,还必须保证持久性,任何已写入的数据都要能在故障中保留下来
协调/信号服务
云函数之间通常采用生产者-消费者模式来共享状态,需要消费者立即得知生产者的数据可用了
同样,一个函数可能需要在满足某种条件时发信号给另一个,或者多个函数可能也想要配合工作,例如实现数据一致性机制。此类信号系统将受益于微秒级延迟、可靠的传输以及广播或群组通信,而且因为云函数实例无法单独寻址,无法用来实现教科书式的分布式系统算法(如 consensus 或 leader election)
最小化启动时间
启动时间分为 3 部分:
调度及启动运行云函数相关资源
下载运行云函数代码所需的应用软件环境(如操作系统、类库)
执行应用程序的特定启动任务,比如加载和初始化数据结构及类库
资源调度和初始化以及配置 VPC 和 IAM 策略会造成很大延迟和开销,云供应商近期专注于通过开发轻量级隔离机制来缩短启动时间
一种办法是利用单核节省开销:
不像传统操作系统一样动态检测硬件、应用用户配置、分配数据结构,而是通过预配置硬件和静态分配数据结构来压缩这些成本
另外,单核只包含应用程序所必须的驱动和系统库,比传统操作系统空间占用低得多
但单核是针对特定应用程序定制的,在运行多个标准内核实时,可能无法实现更进一步的效率提升,比如在同一 VM 中的不同云函数时无法共享内核代码分页,或通过预缓存缩减启动时间
另一种方法是在应用程序实际调用时动态增量加载类库,例如 Azure Functions 里的共享文件系统
特定应用程序初始化由开发者来负责,但云供应商能够在其 API 中提供就绪信号,以避免过早调用云函数。另外,云供应商可以预先执行启动任务,尤其适用于客户无关的任务(比如启动 VM 和流行操作系统及相关类库),因为多租户之间能够共享一个热实例池(warm pool)
网络
前面提到,广播、协调、shuffle 等流行通信机制在云函数环境会带来严重的开销。比如把 K 个云函数打包到一个 VM 实例上的话,云函数版将比 VM 版多发出 K 次(甚至更多)消息,在 shuffle 场景甚至需要 K^2 次消息通信
有 3 种方式解决这个问题:
给提供云函数提供多核,类似于 VM 实例,这样多个任务就能在发送数据之前或收到数据之后合并/共享数据了
允许开发者显式把一些云函数放到同一 VM 实例上,给应用程序提供拆箱即用的分布式通信机制,以便云供应商把云函数分配给同一 VM 实例
让应用程序提供计算图,允许云供应商将相关云函数分配到同一 VM 实例(co-locate),从而最大限度地减少通信开销
但前两种方式会降低云供应商分配云函数的灵活性,导致数据中心的利用率减低。而且有违 Serverless Computing 精神,因为迫使云开发者去考虑系统管理
安全
Serverless 打乱了之前的安全责任划分,将许多责任从云用户转移到了云供应商身上,而并没有从根本上改变它们。然而,Serverless 还必须应对应用程序间多租户资源共享的固有风险
随机调度和物理隔离
物理共同驻留(co-residency)是云环境下硬件级边信道和 Rowhammer 攻击的关键,此类攻击首先要与受害者处于同一物理主机上
云函数的短暂性能在一定程度上限制攻击者识别并发运行的受害者的能力。随机或对手感知(adversary-aware)调度算法能够降低攻击者与受害者位于同一主机的风险,让物理共同驻留攻击更加困难。但这些安全措施可能会与分配(VM)方式的启动时间、资源利用和通信优化产生冲突
细粒度的安全环境
云函数需要细粒度配置,包括访问私钥、存储对象以及本地临时资源。需要从现有的 Serverful 应用转换安全策略,并为云函数中动态使用提供能够充分表达(这些策略的)的安全 API,例如,云函数可能不得不把一些安全特权委托给别的云函数或云服务
在加密保护的安全环境中,基于功能的访问控制机制可能是此类分布式安全模型的自然选择。建议在多方设置中使用信息流控制进行跨函数访问控制,比如为云函数动态创建短期秘钥和证书,但安全机制分布式管理上的其它问题(比如不对等和吊销证书)会加剧
从系统层面来看,用户需要函数级的细粒度安全隔离,至少要作为可选项。而提供函数级沙盒的难点在于保证较短的启动时间,不对重复函数调用以共享状态的方式缓存执行环境。可以通过本地实例快照,让每个函数都可以从干净的状态开始,或者采用轻量级虚拟化技术(比如库操作系统、单核、微 VM 等),能够将启动时间缩减至几十毫秒,但不确定其安全性是否能达到传统 VM 的程度。积极的一面是,Serverless 中的供应商管理和短期实例能够更快地修补漏洞
对于那些想要防护物理共同驻留攻击的用户,一种解决方案是要求物理隔离。云供应商可以为客户提供高级选项,在专用物理主机上启动云函数
模糊的 Serverless
云函数可能会在通信中泄漏访问模式(access patterns)和时序信息(timing information)
对于 serverful 应用,通常批量检索数据并缓存在本地。而由于云函数是短暂的,并且在云环境中广泛分布,网络传输模式可能会泄漏敏感信息(比如自家员工),即便数据是端对端加密的,把 Serverless 应用分解成许多小函数的趋势加剧了这种安全隐患。虽然主要安全问题来自外部攻击者,但也能通过模糊算法来防护来自员工的攻击,然而,这样做的开销通常都很高
架构
硬件异质性、定价以及易管理程度
云计算中占主导地位的 x86 微处理器在性能上几乎没有提升(2017 年单程序性能提升仅 3%),这种趋势持续下去的话,20 年内性能都无法翻番。同样,每个芯片的 DRAM 容量也已接近极限,目前有在售的 16Gbit DRAM,但似乎造不出 32G DRAM 的芯片。唯一值得安慰的是,这种龟速变化让供应商能在旧机器折损时从容更换,而对 Serverless 市场几乎没什么影响
通用微处理器的性能问题并不会减少对更快速计算的需求,有两个方向,对于用高级脚本语言(如 JavaScript 或 Python)编写的函数,可以通过软硬件共同设计产生语言特定的自定义处理器,其运行速度要快 1 到 3 个数量级。另一个方向是特定领域架构(DSA,Domain Specific Architectures),DSA 能够针对特定问题领域量身定制,对该领域有显著的性能和效率提升,但在其它领域表现不佳。图形处理单元(GPU,Graphical Processing Units)长期以来一直用于加速图形处理,我们开始看到机器学习领域的 DSA,比如张量处理单元(TPU,Tensor Processing Units),TPU 能比 CPU 快 30 倍。这只是很多实例中的一例,用 DSA 来增强针对单独领域的通用处理器将成为常态
对于硬件异质性,同样有两个方向:
Serverless 云包含多种实例类型,定价取决于所使用的具体硬件
云供应商能够自动选用基于语言的加速器和 DSA,这种自动化能够基于云函数所使用的的软件库或语言隐式完成,比如 CUDA 代码用 GPU,而 TensorFlow 代码用 TPU。或者,云供应商能够监控云函数的性能并在下次运行时把它们迁移到更合适的硬件上去
对于 x86 的 SIMD 指令,Serverless 正面临着异质性,AMD 和 Intel 通过增加每个时钟周期执行的操作数和新增指令,来快速改进 x86 指令集中的这部分。对于使用 SIMD 指令的应用程序,在最近的 Intel Skylake 微处理器(512 位宽 SIMD 指令)上运行要比旧的 Intel Broadwell 微处理器(128 位宽 SIMD 指令)上快得多。目前 AWS Lambda 中这两种微处理器都以相同价格供应,但 Serverless 用户没有办法表明想用更快的 SIMD 硬件。在我们看来,编译器应该给出哪种硬件最合适的建议
随着加速器在云环境越来越流行,Serverless 云供应商将无法忽视异质性的困境,尤其是因为存在合理的补救措施
七.对 Serverless 的 6 大误解
云函数每分钟的价格更贵,因此 Serverless 比 Serverful 贵
因为 Serverless 的定价不单是资源实例,还包括所有系统管理功能,比如可用性冗余、监控、日志记录以及伸缩。而且,Serverless 伸缩粒度更精细,意味着实际使用的计算量可能更有效率。更重要的是,Serverless 在没有调用云函数时无需付费,因此可能会比 Serverful 便宜得多
Serverless 可能会产生无法预料的成本
对某些用户来说,即用即付也意味着成本不可预测,这与许多组织的预算管理方式相悖,比如审批预算时想要知道未来一年的 Serverless 服务成本。云供应商可以通过提供套餐定价(bucket-based pricing)来缓解这种需求,就像电话公司为特定使用量提供固定费率套餐一样,甚至在 Serverless 普及之后,还能根据历史情况预测出 Serverless 服务成本
Serverless 使用 Python 等高级语言编程,所以很容易移植到不同 Serverless 平台
不同平台下,不仅函数调用、打包的方式不同,而且许多 Serverless 应用还依赖缺乏标准化的 BaaS 产品/服务生态(比如对象存储、KV 数据库、日志和监控等,要实现可移植),必须形成标准化 API,比如 Google 的 Knative 项目在朝着这个方向探索
Serverless 下,供应商绑定(vendor lock-in)程度更强
如果应用程序移植困难就会存在与供应商的强绑定,而框架提供的跨云支持能够缓解这种强绑定
云函数无法应对有极低延迟性能要求的应用程序
Serverful 实例能够处理此类场景是因为它们一直都在运行,能在收到请求后快速响应。但如果云函数的启动延迟对应用程序而言无法满足,可以采取一些策略来缓解,比如通过定期执行云函数来预热
很少有所谓的弹性服务能满足 Serverless 的实际灵活性要求
“弹性”(elastic)在 Serverless 中指的是能够快速变更容量、用户干预越少越好,而且要在不用时能缩减到 0,而云供应商所提供的通常只是有限弹性(比如只允许实例化整数个 Redis 实例、要求显式配置容量、甚至要几分钟才能响应需求变化),并没有达到这些要求,因而失去了许多 Serverless 优势
由于没有明确的技术定义和指标,“弹性”一词是模糊不清的
八.总结和预测
通过提供简化的编程环境,Serverless 让云更易于使用,从而吸引更多用户。Serverless 包括 FaaS 和 BaaS 产品,标志着云编程的重要成熟。省去了如今 Serverful 给应用开发人员带来的手动管理和优化资源的负担,这种成熟就像 40 多年前从汇编语言走向高级语言一样
预测 Serverless 的应用将会暴涨,并且混合云本地应用程序会越来越少,尽管某些部署可能会由于法规约束和数据管制规则而保持现状
虽然已经取得了一定成功,但还存在许多挑战,能够克服这些问题的话,就能让 Serverless 在更广泛的应用程序中流行起来。第一步是 Serverless 临时存储,必须以合理的成本提供低延迟、高 IOPS(的临时存储服务),但无需提供经济实惠的长期存储。第二类应用程序将受益于 Serverless 持久存储,因为它们确实需要长期存储,新的非易失存储器技术可能有助于此类存储系统。其它应用程序将会受益于低延迟的信号服务以及对流行通信机制的支持
Serverless 未来的两个重大挑战是提升安全性和适应可能来自专用处理器的性价比改进,Serverless 已有的一些特性有助于应对这些挑战,例如:
物理共同驻留是边信道攻击的必要条件,在 Serverless 中很难确认(是否处于同一物理机器上),而且很容易采取防护措施,比如随机分布云函数
用高级语言(如 JavaScript、Python 或 TensorFlow)编程的云函数,提升了编程抽象层级,更有利于底层硬件创新
最后,预测 Serverless Computing 在接下来的 10 年里:
将出现新的 BaaS 存储服务,让更多类型的应用程序都能跑在 Serverless 下。此类存储能达到本地数据块存储的性能,分为临时的和持久化的两种。与传统的 x86 微处理器相比,serverless 下计算机硬件的异质性要大得多
将比 serverful 更易于安全编程。得益于高级编程抽象,以及云函数的细粒度隔离
Serverless 的计费模型将会改进,因为其成本没有理由比 serverful 更高。所以 绝大多数以任何规模运行的应用程序在 Serverless 下成本不会更高,甚至更低
Serverful 将用来促进 BaaS 服务。难以在 Serverless 上实现的应用程序(比如 OLTP 数据库或队列等通信机制等),可能会作为云供应商服务集的一部分提供
虽然 serverful 不会消失,但其重要性会随着 Serverless 突破目前的限制而逐渐降低
Serverless 将成为云时代的默认计算模式,在很大程度上取代 serverful,从而结束 Client-Server 时代