写在前面
我们没有办法拥有一块又大、又快、又便宜的存储,所以出现了许多权衡之下的产物:
CPU寄存器:非常快,但不便宜也不大
RAM:不太快也不太大,还算便宜
硬盘:非常便宜而且容量很大,但读写慢
并最终形成了这样的层次结构:

类似的,系统设计中也面临许多权衡取舍:
性能与可扩展性
延迟与吞吐量
可用性与一致性
一.性能与可扩展性
可扩展,意味着服务能以加资源的方式成比例地提升性能:
A service is scalable if it results in increased performance in a manner proportional to resources added.
性能提升体现在能够承担更多的工作量,或者处理更大更重的工作(比如数据量增多)
P.S.当然,增加资源也有可能是为了提升服务的可靠性,比如引入冗余
但加资源也会引入多样性,一些节点可能比其它节点的处理能力更强大,另一些老旧节点可能弱一些,而系统又必须适应这种异质性(heterogeneity),那么依赖均匀性的算法就会对新节点利用不足,继而产生性能影响
二.延迟与吞吐量
延迟(Latency)是指从执行操作到产生结果所需要的时间:
Latency is the time required to perform some action or to produce some result.
其度量单位是时间,例如秒(seconds)、纳秒(nanoseconds),系统时钟周期数(clock periods)等
吞吐量(Throughput)是指单位时间内所能处理的操作数,或能产生的结果数:
Throughput is the number of such actions executed or results produced per unit of time.
通过单位时间所生产的东西来计量,例如内存带宽(memory bandwidth)用来衡量内存系统的吞吐量,而对于Web系统,有这些度量单位:
QPS(Queries Per Second):用来衡量信息检索系统(如搜索引擎、数据库等)在1秒内的搜索流量
RPS(Requests Per Second):请求-响应系统(如Web服务器)每秒所能处理的最大请求数量
TPS(Transactions Per Second):广义上指在1秒内所能执行的原子操作数量,狭义上指DBMS在1秒所能执行的transaction数量
P.S.通常也用QPS衡量Web服务的吞吐量,但更准确的单位是RPS
同样,由于无法兼具低延迟和高吞吐量,所以权衡之下的原则是:
Generally, you should strive for maximal throughput with acceptable latency.
在确保延迟尚可接受的前提下,转而追求最大的吞吐量
三.可用性与一致性
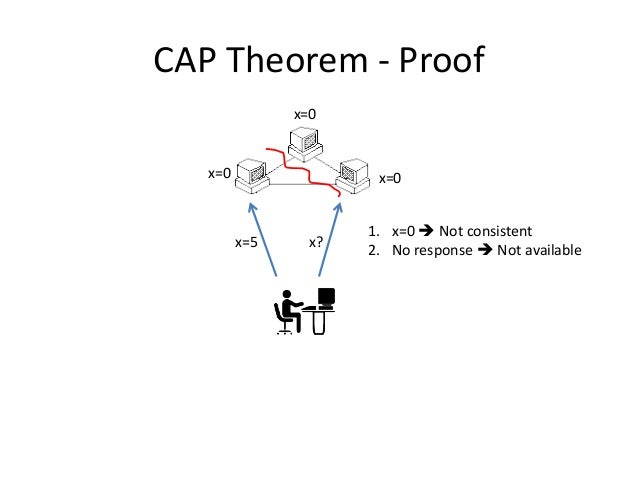
关于可用性与一致性,有个著名的CAP定理:
Of three properties of distributed data systems – consistency, availability, partition tolerance – choose two. —— Eric Brewer, CAP theorem, PODC 2000
在分布式计算机系统中,一致性、可用性和分区容错性三者只能择其二(而且分区容错性必选):
一致性(Consistency):每次读取都能得到最新写入的结果,抑或出错
可用性(Availability):每个请求都能收到正常响应,但不保证返回的是最新信息
分区容错性(Partition Tolerance):即便有一部分由于网络故障down掉了,系统仍能继续运行
因为网络不完全可靠,所以必须保证分区容错性(P必选)。当部分节点出现网络故障时,有2个选择:
取消操作:能确保一致性,但会降低可用性(用户可能收到超时错误),即CP(Consistency and Partition Tolerance),适用于需要原子读写的场景
继续操作:保证可用性,但存在一致性风险(返回的信息可能是旧的),即AP(Availability and Partition Tolerance),适用于可接受最终一致性(Eventual consistency)的场景
也就是说,在P必须满足的前提下(网络故障是系统之外的不可控因素,没得选),只能在C和A之间进行取舍,要么保证一致性(牺牲可用性),要么保证可用性(牺牲一致性),即:
Possibility of Partitions => Not (C and A)
(摘自10. Why do some people get annoyed when I characterise my system as CA?)
P.S.当然,在中心化系统(例如RDBMS)中,不存在网络可靠性的问题,此时C和A能够两全
四.一致性模式
如果同一数据存在多份拷贝,那么就需要考虑如何保证其一致性。而严格的一致性意味着要么读到最新数据,要么出错
但并非所有场景下都需要达到这样的一致性要求,所以出现了弱一致性与最终一致性等妥协产物
弱一致性
写完之后,不一定能读到
弱一致性模式(Weak consistency)适用于网络电话、视频聊天、实时多人游戏等实时场景,而网络电话断线重连后,不会再收到断线期间的通话内容
最终一致性
写完之后,异步复制数据,保证最终能读到
最终一致性模式(Eventual consistency)适用于DNS、email等高可用系统
强一致性
写完之后,同步复制数据,立即就能读到
强一致性模式(Strong consistency)适用于文件系统、RDBMS等需要事务机制的场景
五.可用性模式
可用性保障方面,主要有两种方式:故障转移与复制
故障转移
一个节点down掉之后,迅速用另一个点代替它,以缩减宕机时间。具体的,有两种故障转移模式:
主动-被动(主从故障转移):只由主动服务器处理流量,在工作的主动服务器与待命的被动服务器之间发送心跳包,如果心跳断了,由被动服务器接管主动服务器的IP地址并恢复服务,宕机时间的长短取决于被动机器是热启动还是冷启动
主动-主动(主主故障转移):两台服务器都处理流量,共同承担负载
主动-被动模式下,(切换时)存在数据丢失的风险,而且无论哪种方式,故障转移都会增加硬件资源和复杂度
复制
分为主从复制与主主复制,多用于数据库,暂不展开
可用性指标
可用性通常用几个9来衡量,表示服务可用时间占运行时间的百分比
3个9意味着可用性为99.9%,即:
| 期限 | 宕机时间不得超过 |
|---|---|
| 每年宕机时间 | 8小时45分钟57秒 |
| 每月宕机时间 | 43分钟49.7秒 |
| 每周宕机时间 | 10分钟4.8秒 |
| 每天宕机时间 | 1分钟26.4秒 |
4个9就是99.99%可用:
| 期限 | 宕机时间不得超过 |
|---|---|
| 每年宕机时间 | 52分钟35.7秒 |
| 每月宕机时间 | 4分钟23秒 |
| 每周宕机时间 | 1分钟5秒 |
| 每天宕机时间 | 8.6秒 |
特殊的,对于由多部分组成的服务,其整体可用性取决于这些组成部分是串行的还是并行的:
// 串行
Availability (Total) = Availability (Foo) * Availability (Bar)
// 并行
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
可用性都达不到100%的两个服务组合起来,如果是串行的,其整体可用性会下降(99.9% * 99.9% = 99.8%),而并行的话,整体可用性会提高(1 - 0.1% * 0.1% = 99.9999%)