写在前面
对于 Web 服务而言,提升可扩展性的主要途径是将耗时的同步工作改成异步处理,从而允许将这些工作“外包”给多个 Worker 去做,或者提前完成能够预知的部分
那么,异步机制与可扩展性有什么关系?
这要从(异步)并行处理的优势说起
一.串行、并发与并行
可扩展性,意味着能通过向系统添加资源的方式应对不断增加的工作量
对于多个任务,一般有 3 种执行策略:
串行:一个接一个地同步执行,总耗时为所有任务之和
并发:多 CPU/多核并发执行,总耗时取决于最慢的任务耗时
并行:异步并行执行,总耗时同样取决于最慢的任务耗时
试想,如果工作量持续增长,串行模式的延迟将会越来越大,而且无法通过加资源来解决,可扩展性无从谈起
并发模式虽然可以通过加 CPU 来应对更多的工作量(即纵向扩展),但很快就会遭遇瓶颈,要么达到顶配,要么耗光预算,可扩展性也不是很好
并行模式下,由于任务能够异步执行,我们可以加任意多的 Worker 来分担工作量,可扩展性良好。并且,与并发模式相比,异步处理是非阻塞的(无需等待执行结果,单 CPU/单核就足够了),意味着在(Worker)执行任务的同时,系统仍然能够轻松响应用户请求
因此,相比之下异步(并行)可扩展性最高
二.异步的意义
除了可扩展性方面的优势外,异步更多的意义在于:
可打断/可暂停:允许分片执行,而不必一次做完
可调度:允许更细粒度的时间管理,比如闲时主动执行、甚至离线执行
并行的可能性:异步返回结果,意味着可以交给别人、甚至交给一支军队来做
解耦生产者和消费者:把 Worker 分离出去,使之能够独立扩展,比如只加 Woker 不加 Web Server,类似于分离 Web 层和应用层
所以,React 从同步的 Stack reconciler 改为 Fiber reconciler,也具有这些意义:
既然任务可拆分(只要最终得到完整 effect list 就行),那就允许并行执行(多个 Fiber reconciler + 多个 worker),首屏也更容易分块加载/渲染(vDOM 森林)
(摘自完全理解 React Fiber)
三.消息队列
实现上,最常见的异步机制当然是消息队列:
Message queues provide an asynchronous communications protocol, meaning that the sender and receiver of the message do not need to interact with the message queue at the same time.
由消息队列提供异步通信协议,消息的发送方和接收方不需要同时与消息队列进行交互
例如,邮件系统中,发件人将邮件发出之后,可以继续处理其他内容,而无需等待收件人响应:
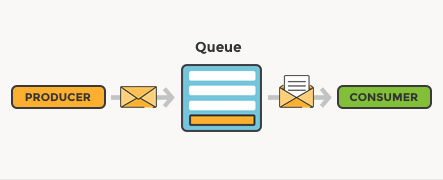
在用户看来,任务是立即完成的,但实际上是在一段时间之后才真正完成(所谓异步)
消息队列的运作中有 3 个角色,消息的生产者、消费者以及经纪人(Broker):
生产者:应用程序往队列里发布任务后,立即告知用户该任务的状态
消费者:Worker 拿到任务并执行,完成之后通知
Broker:从队列里取出任务并分发给 Worker,并负责管理任务的完整性,包括失败重试、(根据 Worker 的实际状态)动态调整分发策略等
P.S.另外,有个非常相似的概念叫任务队列,区别在于消息队列只负责接收、传递消息,任务队列还跟踪执行并返回结果,可以看作特殊的消息队列
Tasks queues receive tasks and their related data, runs them, then delivers their results.
当然,实际的消息队列/任务队列的实现更复杂一些,需要考虑各种问题:
消息可能会丢失:比如消费者挂了,甚至消息队列挂了
消息可能会重发多次:比如消费者做完忘记发送完成回执(ack)了
可能出现忙闲不均的情况:比如轮流分发的话,有些 Worker 接到的总是重活儿
队列可能会溢出:比如 Worker 太少或太忙,导致消息迅速堆积
P.S.关于消息队列运作机制和使用场景的更多信息,见RabbitMQ Tutorials
四.漏斗模型
消息队列就像一个漏斗(把橄榄油倒进瓶子里),用来控制流量和流速:

汹涌而至的消息从敞口流入,经过缩口以固定的流速输出给(消息的)消费者
如果生产速率始终低于消费速率,倒进来立即就流走了,那么就不需要漏斗(消息队列)
如果生产速率始终大于消费速率,就会在漏斗中累积,最终填满、溢出,导致消息丢失:

P.S.这种现象称为Back pressure(反向压力),下游消费速度限制了传输,此时可以限制队列大小,排满了就返回 503,稍后重试(比如采取指数退避策略,让重试间隔越来越长)
所以,只有生产速率在短期内大于(而不是始终大于)消费速率的情况下,漏斗才有意义——用来吸收暂时的超量生产量:
The message queue provides temporary message storage when the destination program is busy or not connected.
五.利特尔法则
另外,排队理论中一个有名的定理叫利特尔法则(Little’s law):
L = λW
L: average number of items in the queuing system
W: average waiting time in the system for an item
A: average number of items arriving per unit time
适用于任何稳定运转的排队系统:
A “queuing system” consists of discrete objects we shall call “items” that “arrive” at some rate to the “system.” Within the system the items may form one or more queues and eventually receive “service” and exit.
P.S.“稳定运转”,是指不包括系统启动、退出等过渡状态
一些 item 以某种速度到达系统,开始排队,最终排到服务并从队列中退出:
到达 -> 排队 -> 离开
L = λW就是说:
队伍的平均长度 = 平均到达速度 * (每一项的)平均等待时间
例如:
酒窖:偶尔买一瓶放进去,平均每个月买 8 瓶,朋友聚会时候喝掉一些,但多数时候窖里都有 160 瓶,那么,就可以知道取出来喝的时候,每瓶酒在酒窖里平均存放了 1.67 年(
W = 160 / (8 * 12)),离陈酿还有一段距离邮箱:平均每天收到 50 封新邮件,邮箱里多数时候有 150 封未读邮件,那么平均每 3 天(
W = 150 / 50)处理一封邮件,可以作为邮件处理效率的衡量标准工厂:每天平均加工 1000 份原材料,在制品(WIP, work-in-process)数量平均有 45000 个,那么每件产品的加工周期是 45 天(
W = 45000 / 1000),周期比较长医院:某地区平均每天诞生 5 名新生儿,待产妈妈平均会在产房待 2.5 天,那么,产房通常住有 12.5 位(
L = 5 * 2.5)待产妈妈,也就是说,产房床位不能少于 13 张,对应的医护人员也不能太少
三项中,只要知道两个(易知的)就能粗略得出另一个(难算的),这就是利特尔法则的意义