写在前面
为了解决数据库层的扩展问题,我们已经讨论了两种方案:
Replication:从单库扩展到多库,以承载更多的请求量
Partitioning:把单库(表)拆分成多库(表),打破单库的性能瓶颈
在(多机)多库多表的加持下,激增的请求量、数据量已经不再是难题,然而,除却数据量外,还有一个极其影响单库性能的因素——数据的组织方式
例如,在关系型数据库中,数据实体用二维表格(称为实体表)来描述:
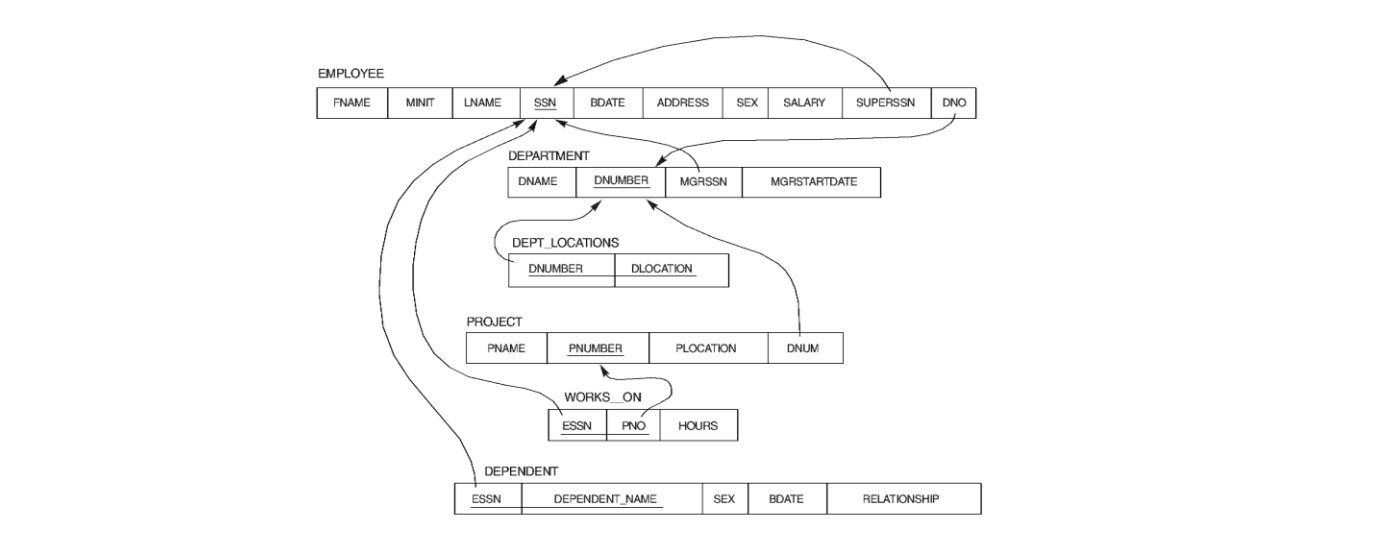
实体之间的复杂关联关系(多对多)也通过二维表格(称为关系表)来描述:
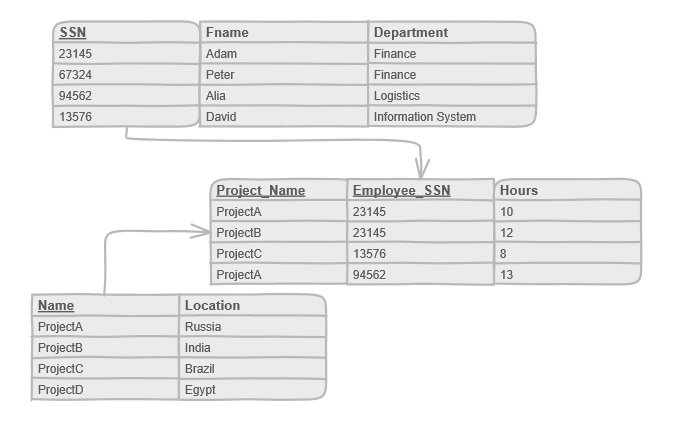
因而经常需要多表联查才能得到目标信息,关系越复杂,读取性能越差,并最终像数据量一样成为单库性能瓶颈,制约着数据库层的可扩展性
那么,对于关系型数据库,有办法进一步提升数据读取性能吗?
有,(在一定程度上)改变数据的组织方式,即反范式化(Denormalization)
一.范式化
在讨论反范式化之前,有必要先明确什么是范式化,要反的东西是什么?
Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity.
范式化(Database normalization),就是按照一系列范式(Normal forms)要求来组织数据模型的过程,目的是减少数据冗余,提高数据完整性
试想,如果相同的信息在多行中重复出现,不相干的信息也凑在同一张表中,就很容易出现一些异常情况:
更新异常:只更新单行,就会出现逻辑上的不一致
插入异常:无法只插入部分信息,除非让其它列先留空
删除异常:删除部分信息的同时,可能会波及其它无关信息
为了避免这些异常情况,人们提出了一些约束规则,即数据库设计范式
二.数据库设计范式
1NF:第一范式(First normal form)要求数据表中每个字段的值都不可再分
2NF:第二范式(Second normal form)在满足 1NF 的基础上,要求所有非主属性都完全依赖于其主键
3NF:第三范式(Third normal form)在满足 2NF 的基础上,要求所有非主属性都不传递依赖于任何主键
P.S.此外,还有BCNF、4NF、5NF等等,具体见Normal forms
类比应用层,设计范式相当于数据层的设计模式,对数据表进行解耦,使单表信息更加内聚,彼此边界分明,依赖关系更加清晰
我们一般把满足 3NF 的关系模式(Relation schema)称为规范化的(Normalized),大多数情况下都能规避上面提到的插入、更新和删除异常。然而,在解决这些问题的同时,范式化也带来了另一些问题
三.范式化的弊端
在这些设计范式的约束下,相关联的信息被存储到了不同的逻辑表中:
A normalized design will often “store” different but related pieces of information in separate logical tables (called relations).
例如:
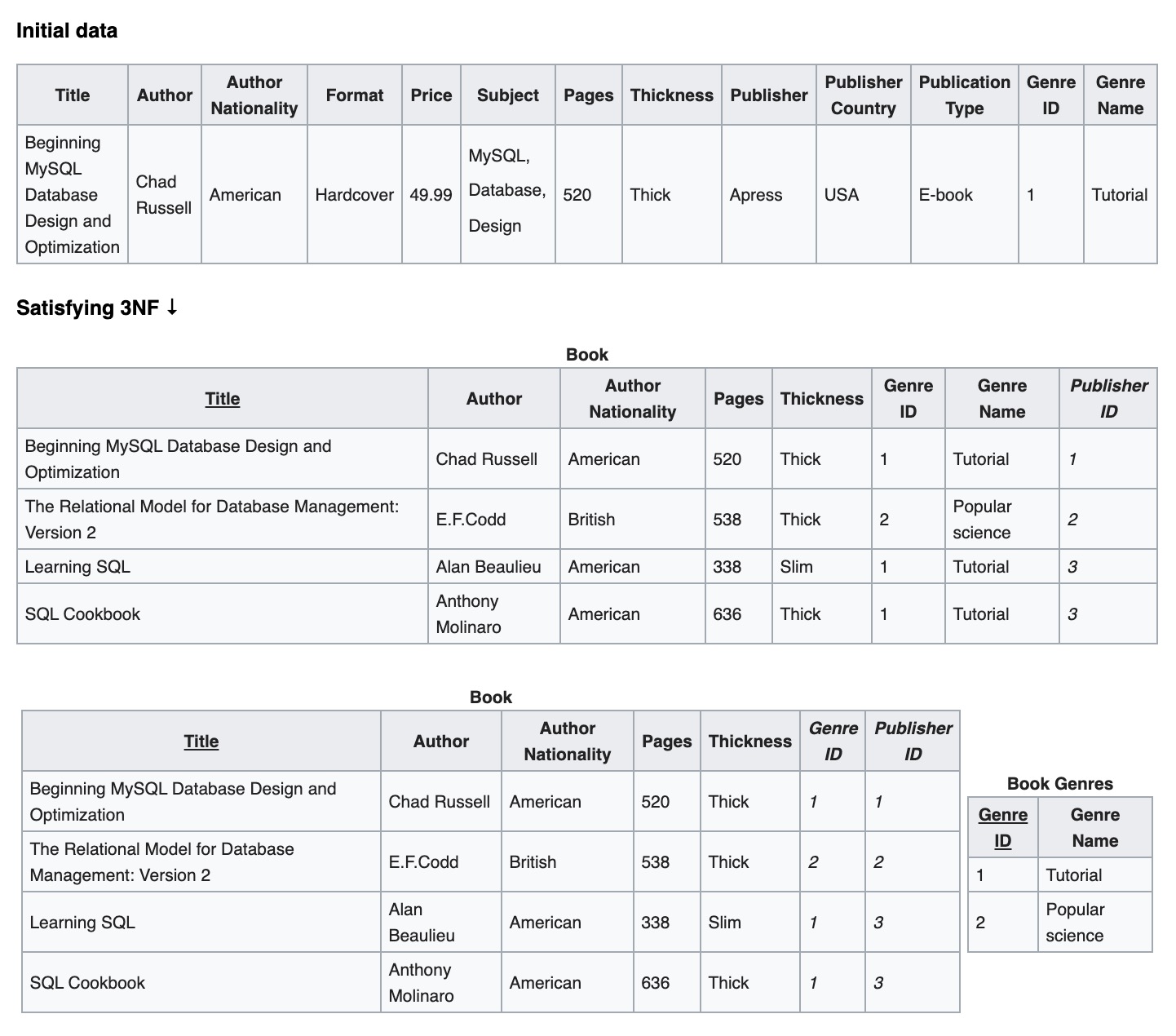
3NF
以致于经常需要多表联查(join操作),关系越复杂,连表查询越慢:
If these relations are stored physically as separate disk files, completing a database query that draws information from several relations (a join operation) can be slow. If many relations are joined, it may be prohibitively slow.
那么,有办法能改善查询性能吗?
有。引入冗余:
允许 DBMS 存储额外的冗余信息,例如索引视图(indexed views)、物化视图(materialized views),但仍遵从设计范式
增加冗余数据,减少
join操作,打破设计范式(即反范式化)
四.反范式化
所谓反范式化,是一种针对遵从设计范式的数据库(关系模式)的性能优化策略:
Denormalization is a strategy used on a previously-normalized database to increase performance.
P.S.注意,反范式化不等于非范式化(Unnormalized form),反范式化一定发生在满足范式设计的基础之上。前者相当于先遵守所有规则,再进行局部调整,故意打破一些规则,而后者全然不顾规则
通过增加冗余数据或对数据进行分组,牺牲一部分写入性能,换取更高的读取性能:
In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data.
在设计范式的约束下,数据表中没有冗余信息(某个数据只存放在某张表的某个单元格中),为了得到某个数据可能需要一系列的跨表查询,因而读操作性能不佳,但写操作很快,因为更新数据时只需要修改一处
反范式化就是要打破这种约束,把某些数据在不同的地方多放几份,以加快数据检索速度:
The opposite of normalization, denormalization is the process of putting one fact in many places.
具体操作
具体地,常见做法如:
存一些派生数据:类似于往 Redux Store 中塞计算属性,把需要频繁重复计算的结果存起来,例如在一对多关系中,把“多”的数量作为“一”的属性存储起来
预先连接(pre-joined)生成汇总表:把需要频繁
join的表提前join好采用硬编码值:把依赖表中的常量值(或者不经常变化的值)直接硬编码到当前表中,从而避免
join操作把详情信息纳入主表中:对于数据量不大的详情表,可以把全部/部分详情信息塞到主表中,以避免
join操作
P.S.关于反范式化具体做法的更多信息,见When and How You Should Denormalize a Relational Database
五.反范式化的代价
但除非必要,一般不建议反范式化,因其代价高昂:
失去了数据完整性保障:打破范式,意味着之前通过范式化解决的更新、插入、删除异常问题又将重新冒出来,也就是说,冗余数据的一致性要靠 DBA 自己来保证,而不像索引视图等由 DBMS 来保证
牺牲了写入速度:由于反范式化引入了冗余数据,更新时要修改多处,但大多数场景都是读密集的,写入慢一点问题不大
浪费了存储空间:存储了不必要的冗余数据,自然会浪费一些存储空间,但空间换时间一般是可接受的(毕竟内存、硬盘等资源已经相对廉价了)
P.S.一般通过约束规则(constraints)来保证冗余数据的一致性,但这些规则又会抵消一部分作用