写在前面
本文第一部分翻译自REST 2.0 Is Here and Its Name Is GraphQL,标题很有视觉冲击力,不小心上钩了
剩余部分是对GraphQL的思考。现在,我们边看译文边汇聚疑问
一.译文
GraphQL是一种API查询语言。虽然与REST有本质区别,但GraphQL可以作为REST的备选项,它提供了高性能、良好的开发体验和一些强大的工具
通过本文,我们来看看怎样用REST和GraphQL来处理一些常见场景。本文附有3个项目,提供了流行电影和演员信息API,还用HTML和jQuery搭了个简单的前端应用,可以查看对应的REST和GraphQL源码
我们将通过这些API来看这两种技术的差异,以便了解其优缺点。开始之前,先布置舞台,快速过一下这些技术是怎么冒出来的
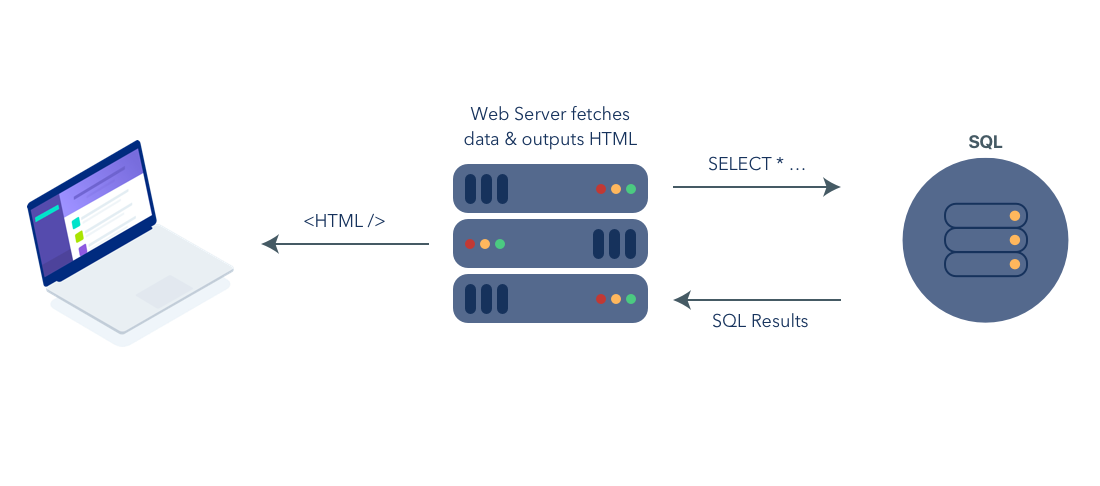
Web早期
Web早期很简单,早期的Web应用就是静态HTML文档。演化到网站想包含存在数据库(例如SQL)里的动态内容,并通过JavaScript来添加交互功能。绝大多数的Web内容都通过桌面电脑的Web浏览器来访问的,看起来一切都很美好
REST:API的出现
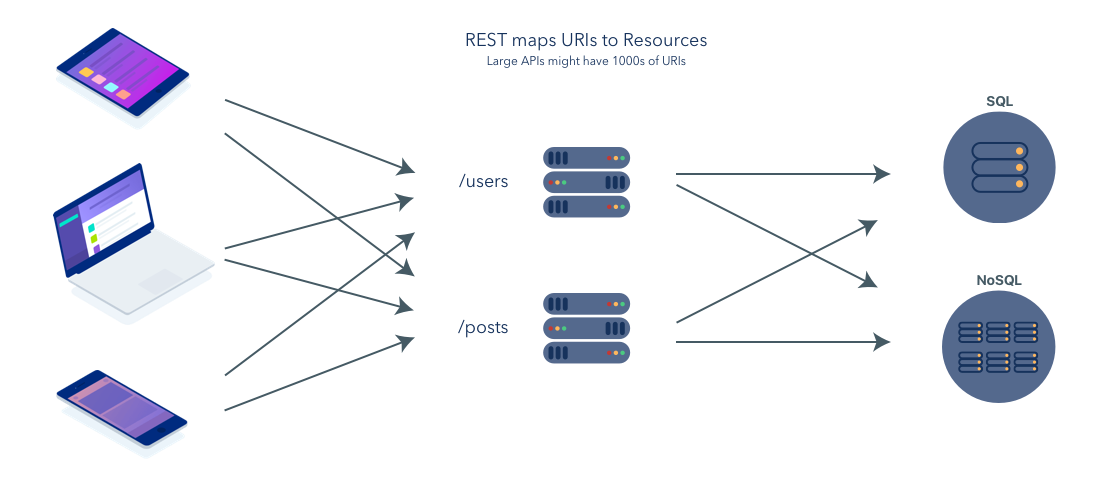
快进到2007年Steve Jobs介绍iPhone的时候,除了智能手机对世界、文化和交流的深远影响,也让开发者的工作变复杂了很多。智能手机破坏了开发现状,短短几年后,我们突然就有了桌面电脑、iPhone、Android和平板电脑
作为回应,开发者开始用RESTful API给形状各异、尺寸不同的应用提供数据,新的开发模型差不多是这样:
GraphQL:API的演进
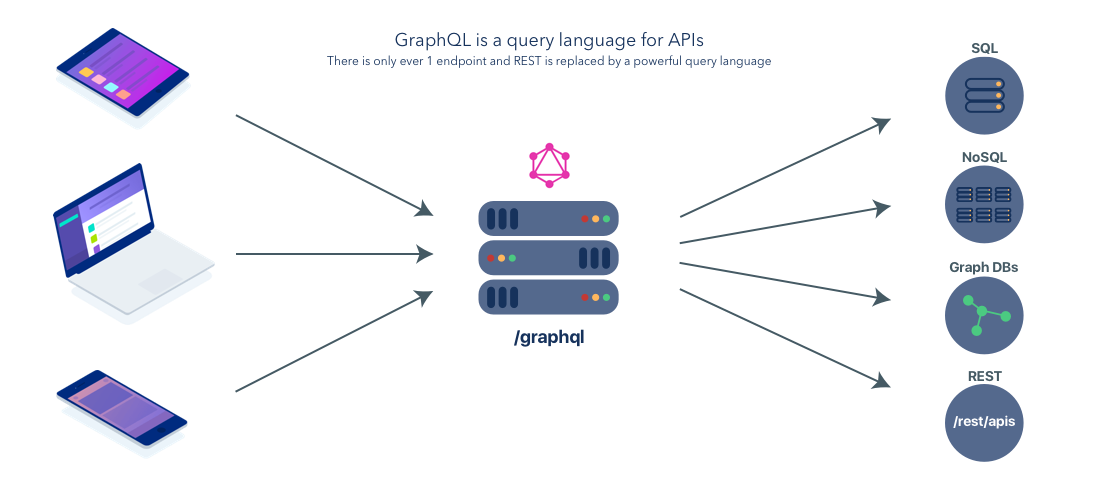
GraphQL是一种API查询语言,由Facebook设计并开源。可以把GraphQL当做REST的备选项来构建API,而REST是一种概念模型,可以用来设计和实现API。GraphQL是一种标准化的语言、type系统和在客户端和服务器之间建立起强约定的规范定义。让所有设备之间通信有了一套标准语言,简化了创建大型跨平台应用的过程
用GraphQL的话,图就变成了这样子:
GraphQL vs REST
下面的部分,建议跟着源码走,可以在accompanying GitHub repo找到本文相关源码
源码包含3个项目:
RESTful API实现
GraphQL API实现
一个用jQuery和HTML搭的简单客户端网页
为了尽量简单地对比这两种技术,项目故意设计得很简单
想跟着做的话,先打开3个终端窗口,再cd到项目库的RESTful、GraphQL和Client目录,通过npm run dev启动服务。准备好这些再接着往下看:)
通过REST查询
我们的RESTful API还有一些端点(endpoints):
| Endpoint | Description |
|---|---|
| /movies | returns an Array of objects containing links to our movies (e.g. [ { href: ‘http://localhost/movie/1’ } ] |
| /movie/:id | returns a single movie with id = :id |
| /movie/:id/actors | returns an array of objects containing links to actors in the movie with id = :id |
| /actors | returns an Array of objects containing links to actors |
| /actor/:id | returns a single actor with id = :id |
| /actor/:id/movies | returns an array of objects containing links to movies that the actor with id = :id has acted in |
注意:我们这么简单的数据模型就已经有6个端点要维护和建立文档了
一起想象一下我们是客户端开发者,需要用这些movie API通过HTML和jQuery来构建一个简单的网页。为了构建这个页面,我们需要关于movie和对应actor的信息。我们的API具备我们需要的所有功能,所以直接获取数据
开个新终端执行:
curl localhost:3000/movies
应该会得到这样的响应:
[
{
"href": "http://localhost:3000/movie/1"
},
{
"href": "http://localhost:3000/movie/2"
},
{
"href": "http://localhost:3000/movie/3"
},
{
"href": "http://localhost:3000/movie/4"
},
{
"href": "http://localhost:3000/movie/5"
}
]
以RESTful方式,API返回一个链接数组,每个链接对应实际的电影对象。然后执行curl http://localhost:3000/movie/1来获取第一个电影,第二个就curl http://localhost:3000/movie/2……以此类推
在app.js可以看到我们用来获取页面需要的所有数据的方法:
const API_URL = 'http://localhost:3000/movies';
function fetchDataV1() {
// 1 call to get the movie links
$.get(API_URL, movieLinks => {
movieLinks.forEach(movieLink => {
// For each movie link, grab the movie object
$.get(movieLink.href, movie => {
$('#movies').append(buildMovieElement(movie))
// One call (for each movie) to get the links to actors in this movie
$.get(movie.actors, actorLinks => {
actorLinks.forEach(actorLink => {
// For each actor for each movie, grab the actor object
$.get(actorLink.href, actor => {
const selector = '#' + getMovieId(movie) + ' .actors';
const actorElement = buildActorElement(actor);
$(selector).append(actorElement);
})
})
})
})
})
})
}
正如你注意到的,看起来不太理想。为了完成这一切,我们做了1 + M + M + sum(Am)次API调用,其中M是movie数量,sum(Am)是M部电影中所有actor的总数。对于小数据需求的应用可能还行,但不适用于大型生产系统
结论呢?我们简单的RESTful方法不合适,为了优化API,我们可能找后端团队要一个专用的/moviesAndActors接口来支持这个页面。只要这个接口好了,我们就可以把1 + M + M + sum(Am)次网络请求换成1次请求
curl http://localhost:3000/moviesAndActors
会返回一个这样的响应:
[
{
"id": 1,
"title": "The Shawshank Redemption",
"release_year": 1993,
"tags": [
"Crime",
"Drama"
],
"rating": 9.3,
"actors": [
{
"id": 1,
"name": "Tim Robbins",
"dob": "10/16/1958",
"num_credits": 73,
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BMTI1OTYxNzAxOF5BMl5BanBnXkFtZTYwNTE5ODI4._V1_.jpg",
"href": "http://localhost:3000/actor/1",
"movies": "http://localhost:3000/actor/1/movies"
},
{
"id": 2,
"name": "Morgan Freeman",
"dob": "06/01/1937",
"num_credits": 120,
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BMTc0MDMyMzI2OF5BMl5BanBnXkFtZTcwMzM2OTk1MQ@@._V1_UX214_CR0,0,214,317_AL_.jpg",
"href": "http://localhost:3000/actor/2",
"movies": "http://localhost:3000/actor/2/movies"
}
],
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BODU4MjU4NjIwNl5BMl5BanBnXkFtZTgwMDU2MjEyMDE@._V1_UX182_CR0,0,182,268_AL_.jpg",
"href": "http://localhost:3000/movie/1"
},
...
]
太好了!只用1个请求,我们就能取到页面需要的所有数据。在Client目录的app.js可以看到这个优化具体实现:
const MOVIES_AND_ACTORS_URL = 'http://localhost:3000/moviesAndActors';
function fetchDataV2() {
$.get(MOVIES_AND_ACTORS_URL, movies => renderRoot(movies));
}
function renderRoot(movies) {
movies.forEach(movie => {
$('#movies').append(buildMovieElement(movie));
movie.actors && movie.actors.forEach(actor => {
const selector = '#' + getMovieId(movie) + ' .actors';
const actorElement = buildActorElement(actor);
$(selector).append(actorElement);
})
});
}
我们的新应用会比之前的版本更快一些,但还不够完美。如果打开http://localhost:4000看我们的页面的话,会看到:
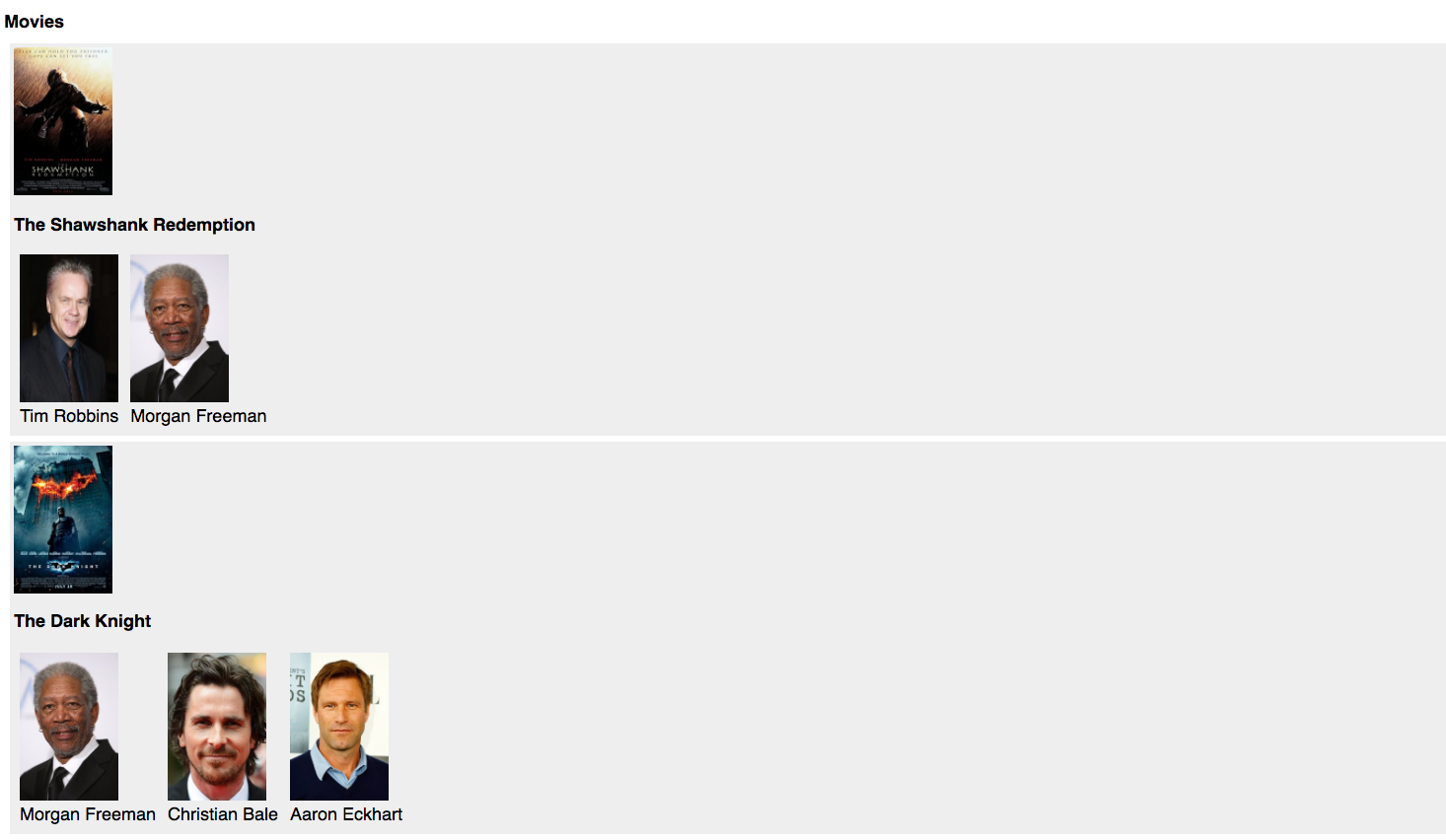
仔细看的话,会注意到我们的页面只用到了movie的title和image以及每个actor的name和image(其实,我们只用到了movie对象8个字段中的2个,和actor对象7个字段中的2个)。也就是说我们浪费了从网络请求拿到的3/4的信息!这样过分使用带宽会非常影响性能,还会带来额外基础设施成本
机智的后端开发者会轻蔑一笑,并快速实现个特殊的查询参数叫fields,接受一组字段名,可以动态决定具体请求应该返回哪些字段
例如,我们可能会用curl http://localhost:3000/moviesAndActors?fields=title,image代替curl http://localhost:3000/moviesAndActors。甚至还会有另一个特殊查询参数actor_fields,用来指定actor模型应该含有哪些字段,例如curl http://localhost:3000/moviesAndActors?fields=title,image&actor_fields=name,image
现在,这差不多是我们的简单应用的最佳实现了,但它引入了一个坏习惯,为客户端应用中特定的页面创建订制化接口。当开始构建一个与网页和Android应用展示信息不同的iOS应用时,这个问题会更加明显
如果我们可以构建一个通用的API,显式说明我们数据模型中的实体和这些实体之间关系,又不会带来1 + M + M + sum(Am)的性能问题,那该多好啊?好消息!我们能做到!
用GraphQL查询
用GraphQL的话,我们可以直接跳到最佳查询,通过一条简单直观的查询,一点不冗余地获取我们需要的所有信息:
query MoviesAndActors {
movies {
title
image
actors {
image
name
}
}
}
强烈建议!手动试试,打开http://localhost:5000的GraphiQL(一个很棒的浏览器GraphQL IDE),执行上面的查询
现在,我们稍微深入一点
想想GraphQL
GraphQL采用了一种与REST完全不同的API方法,没有依赖HTTP结构,比如动词和URI,而是在数据之上提出了直观的查询语言和强大的type系统层,提供客户端和服务器之间的强约定,查询语言提供了一种让客户端开发者可以永久获取任何页面想要的任意数据的机制
GraphQL鼓励把数据看作一个虚拟信息图,包含信息的实体叫做type,这些type可以通过fields彼此关联。查询从根开始,遍历这个虚拟图需要的信息
这个“虚拟图”叫做schema,schema是构成API数据模型的type、interface、enum和union的集合。GraphQL还包含了一种方便的schema语言,可以用来定义我们的API。例如,这就是我们movie API对应的schema:
schema {
query: Query
}
type Query {
movies: [Movie]
actors: [Actor]
movie(id: Int!): Movie
actor(id: Int!): Actor
searchMovies(term: String): [Movie]
searchActors(term: String): [Actor]
}
type Movie {
id: Int
title: String
image: String
release_year: Int
tags: [String]
rating: Float
actors: [Actor]
}
type Actor {
id: Int
name: String
image: String
dob: String
num_credits: Int
movies: [Movie]
}
type系统开启了一大堆好东西的大门,包括更好的工具,更好的文档和跟高效的应用。这块能扯的东西太多,但现在,我们先跳过,关注更多展示REST与GraphQL差异的场景
GraphQL vs Rest:版本控制
用google随便搜一下就能得到关于(或者涉及)REST API版本控制的很多观点。这里不深入探究,只是想强调这是一个有意义的问题。版本控制难的一个因素是通常很难知道什么信息在被哪些应用和设备使用
添加信息一般很容易,无论是REST还是GraphQL,添加字段的话,会流入REST客户端,而会被GraphQL安全忽略,除非改变查询。然而,删除和编辑信息就大有不同了
在REST方式中,很难知道字段级的哪些信息被使用了。我们能知道一个接口/movies被用了,但不知道客户端在用titl,image,还是2个都用了。一种可行的解决方案是添加一个查询参数指定返回哪些字段,但这些参数通常都是可选的。因此,经常看到端点级的变化,比如引入一个新端点/v2/movies。这样可以,但增加了我们API的表面积,同时给开发者带来了不断更新和提供详尽文档的负担
GraphQL中的版本控制则不同,每个GraphQL查询都需要准确描述什么字段被请求了。这种强制要求,意味着我们精确知道什么信息被请求了,并允许我们进一步询问请求频率和由谁发起。GraphQL也支持用废弃字段和废弃原因信息修饰一个schema的原语(primitives)
GraphQL中的版本控制:

GraphQL vs REST:缓存
REST里的缓存直接而高效,实际上,缓存是REST的6个原则约束之一,被内置到了RESTful设计里。如果一个来自/movies/1端点的响应说可以缓存,将来对/movies/1的任何请求都可以简单的换成缓存里的东西,非常简单
GraphQL中的缓存处理稍微有些不同,缓存一个GraphQL API通常需要对API的每个对象引入某种唯一标识。每个对象都有一个唯一标识符的话,客户端可以建立标准化的缓存,用这个标识符来做可靠的缓存、更新和过期。客户端发起引用该对象的下游查询时,就用该对象的缓存版本。如果想知道关于GraphQL缓存原理的更多信息,有一篇好文章深入讨论了这个话题
GraphQL vs REST:开发体验
开发体验是应用开发很重要的一方面,也是我们作为工程师投入很多时间构建好工具的原因。这里的对比是有些主观的,但我认为仍有必要提及
尝试REST,并且它确实有一套丰富的工具生态系用,帮助开发者建立文档、测试和检查RESTful API。说到这里,开发者为REST API的扩展付出了巨大代价。接口数量瞬间爆炸,不一致性越来越明显,版本控制越来越困难
GraphQL在开发体验方面确实有过人之处。type系统已经打开了各种不可思议的工具的大门,比如GraphiQL IDE,以及文档内置到schema里。GraphQL里只有一个端点,并且不依赖文档来找那些数据可用,你拥有了一个类型安全的语言并且能够自动补全可用的东西,用这个来快速创建API。GraphQL也能配合流行的前端框架和工具使用,比如React和Redux。如果考虑用React构建应用的话,强烈推荐看看Relay或者Apollo client
总结
GraphQL提供了一些自用的强大工具集,用来构建高效的数据驱动应用。REST不会立刻消失,但会有很多需要的东西,尤其是要构建客户端应用时
如果想进一步深入了解,请查看Scaphold.io’s GraphQL Backend as a Service,AWS分分钟部署能用于生产的GraphQL API,然后就可以订制扩展自己的业务逻辑了
希望您喜欢这篇文章,有任何想法或者评论,我都很乐意交流,感谢阅读!
二.思考
多一层接口之上的抽象,确实能够带来更大灵活性,比如只需要实现原子接口,就能自由组合出返回内容
注意:上面的译文说GraphQL是数据之上的抽象,实际上应该是接口上的抽象(只是接口概念弱化了,不对外,弱化的接口更接近SQL语句之类的东西),如果每一个字段都对应一个查询接口,那么很容易实现一个通用的接口管理层,来完成GraphQL的所有功能。事实上,GraphQL就是提供了这样的通用定义
那么最大的问题应该是存在冗余查询,因为能自由组合field返回的前提是先精确到field级。也就是说本来一个强接口返回一堆字段,现在要求每个字段都提供一个弱接口,这样才能根据一条自定义查询,精确组装出返回内容
当然,可以通过查询优化来缓解一部分冗余查询,比如根据字段依赖关系,对字段打包查询。但复杂场景下,这种优化可能并不容易实现
如果有一个数据库(或者抽象查询层)内置了这种优化,解决性能问题,那么相信GraphQL将获得压倒性的优势,首先再也不用无休止的加接口加接口了,另外维护一组标准统一的东西,和维护n个接口且存在同一接口不同版本的情况,几乎不用思考如何选择
至于前端生态配合(Redux毕竟不那么通用),明显不算是大问题
因为后端丢弃数据没有成本,所以冗余查询显然不是问题,graphql实际没有为后端引入更高成本。不过确实,想要应用完美的(往往没有必要)无冗余后端,需要数据存储部分的重新设计。 全局地来说,最高效、优化最完美的系统,最终总是所有计算完全由输出决定的批处理系统(不是指操作系统)。graphgl使输出的需求定义可以穿透到更深的地方,让后端有机会为输出形式进行优化。如果实现一种后端,让这种穿透到达cache、数据库,甚至磁盘读写,就可以—— 召唤神龙了吧